Current LLMs almost always process groups of characters, called tokens, instead of processing individual characters. They do this for performance reasons: Grouping 4 characters (on average) into a token reduces your effective context length by 4×.

Current LLMs almost always process groups of characters, called tokens, instead of processing individual characters. They do this for performance reasons: Grouping 4 characters (on average) into a token reduces your effective context length by 4×.
I deal with a lot of servers at work, and one thing everyone wants to know about their servers is how close they are to being at max utilization. It should be easy, right? Just pull up top or another system monitor tool, look at network, memory and CPU utilization, and whichever one is the highest tells you how close you are to the limits.
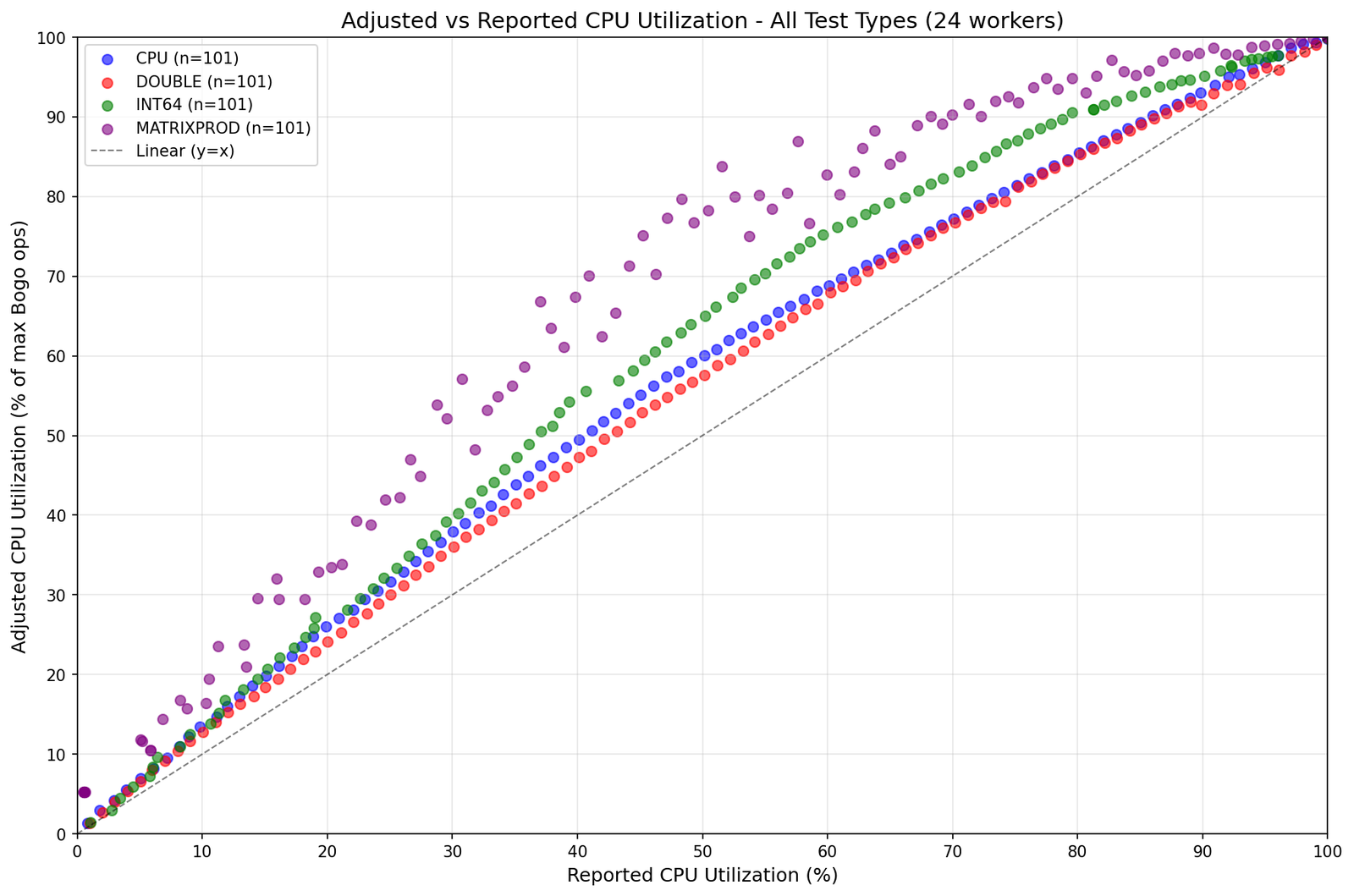
There’s an LLM training optimization which keeps surprising me. It makes loss look unrealistically good during training, especially when training reasoning models with SGD. I’m also starting to think it’s the reason LLMs have trouble fixing their mistakes and take their own outputs too canonically.
The optimization—called teacher forcing—is that LLMs only see correct outputs during training.
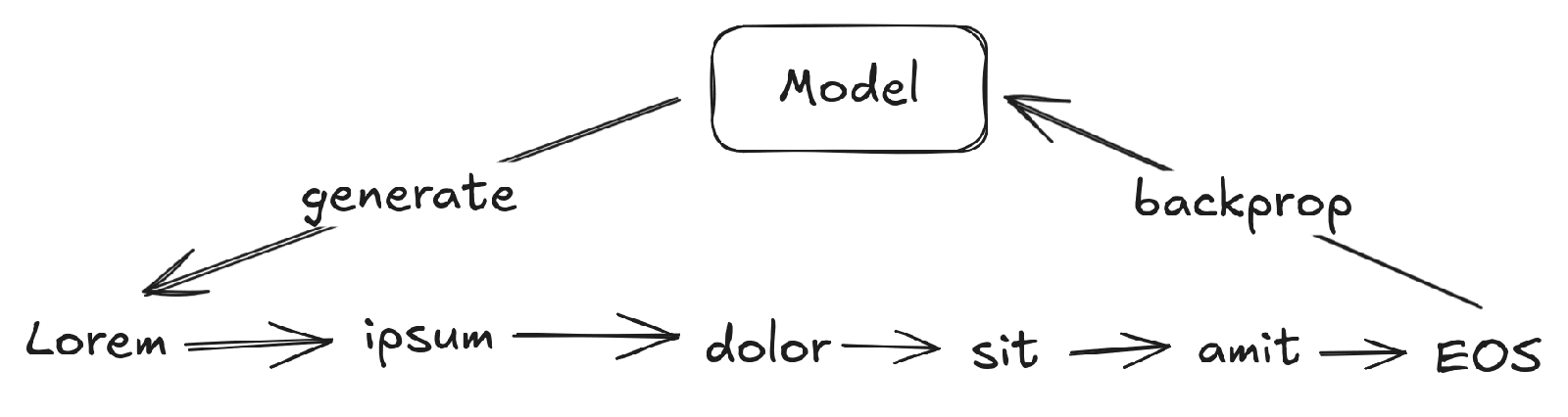
I was thinking about LLM tokenization (as one does) and had a thought: We select the next output token for an LLM based on its likelihood, but (some) shorter tokens are more likely.
Why? Longer tokens can only complete one word, but some shorter tokens can complete many words. Those shorter common tokens are (correctly) learned to be higher-probability because they have the combined probability of any word they could complete. However, standard generation techniques will only consider a subset of probabilities (top-K) and scale the largest probabilities (temperature). Both of these will take the highest probabilities and increase them further, meaning short/common tokens become significantly more likely to be generated just because they’re shorter.
I’ve gone snowboarding about 30 times since I started learning a few years ago, but every time I’m on a lift, most of the other riders have been out 90 days just this season. In fact, almost everyone I see has been skiing or snowboarding for decades, and comes out almost every day.
It’s hard to stay motivated when I’m the worst snowboarder on the mountain.
This might seem like a big coincidence, but I’m also one of the worst runners I know AND one of the worst writers that I’m aware of.
