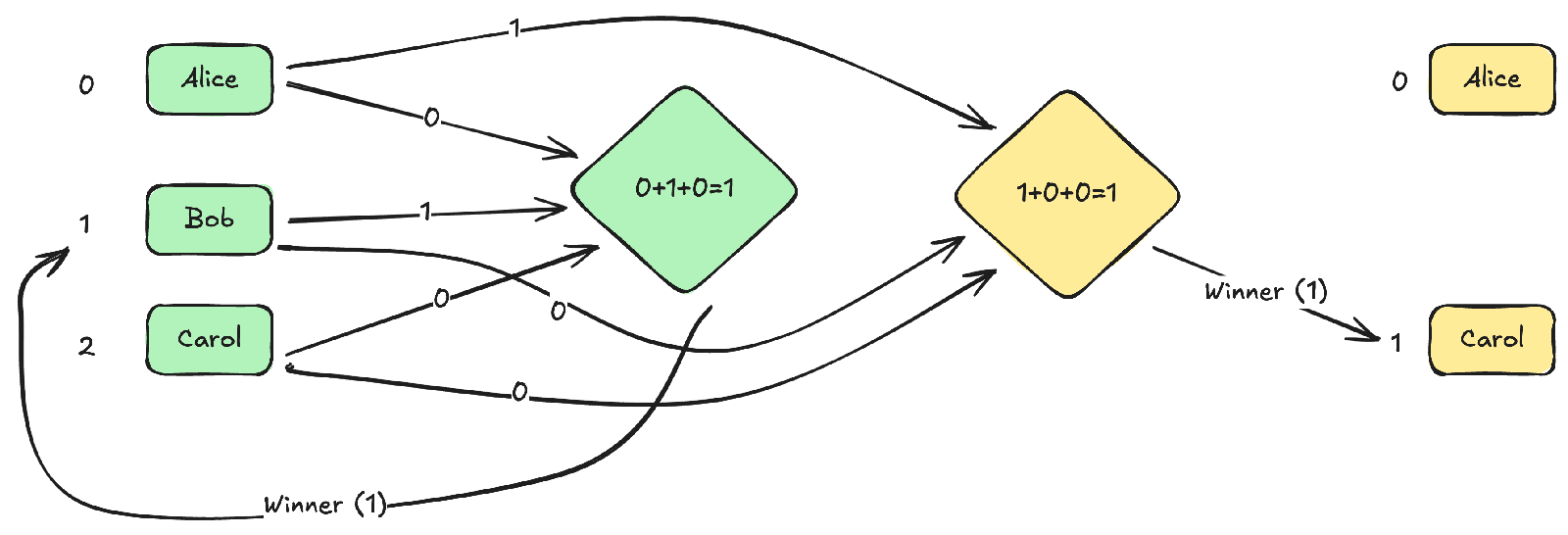
I was thinking about an approval-style voting system that could end with a large number of ties, and ran into the problem of how to break ties in a provably-fair way that doesn’t depend on candidates trusting each other and won’t make voters’ eyes glaze over.
I think I found a solution which is provably-fair, but it might still cross over into eye-glazing territory. I don’t know if this is practical (or novel), but I’m writing it up in case anyone else finds it interesting.
I recently moved near Seattle, where traffic is terrible but there are surprisingly many bike lanes. Unfortunately, there are also a lot of hills. For a while, I would occasionally bike to work, but the hills were intimidating and I had to re-motivate myself every morning. Around a year ago, I finally gave up and just got an e-bike.
I’ve been working remotely since before it was cool, and one thing I wish more people paid attention to is meeting equipment. It’s annoyingly common to join a remote meeting with someone on flaky WiFi, with a barely-understandable microphone, and a camera where they show up as a shadowy blob.
All of this is fixable, and if you work remotely it’s worth spending a little bit of money to do it. Remote meetings where you can see and (more importantly) hear each other clearly are much nicer, and lead to more natural and collaborative conversations.
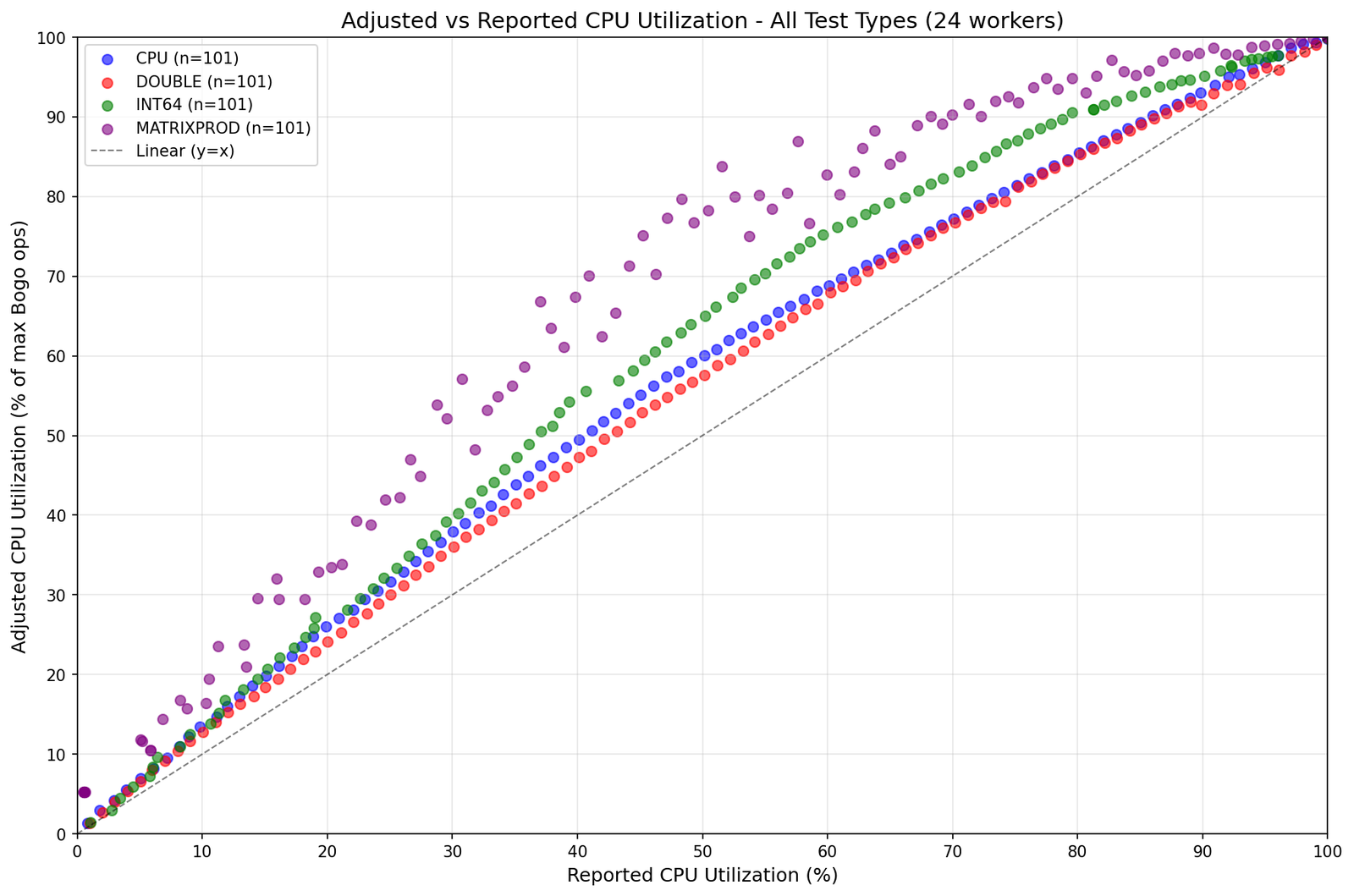
I deal with a lot of servers at work, and one thing everyone wants to know about their servers is how close they are to being at max utilization. It should be easy, right? Just pull up top or another system monitor tool, look at network, memory and CPU utilization, and whichever one is the highest tells you how close you are to the limits.
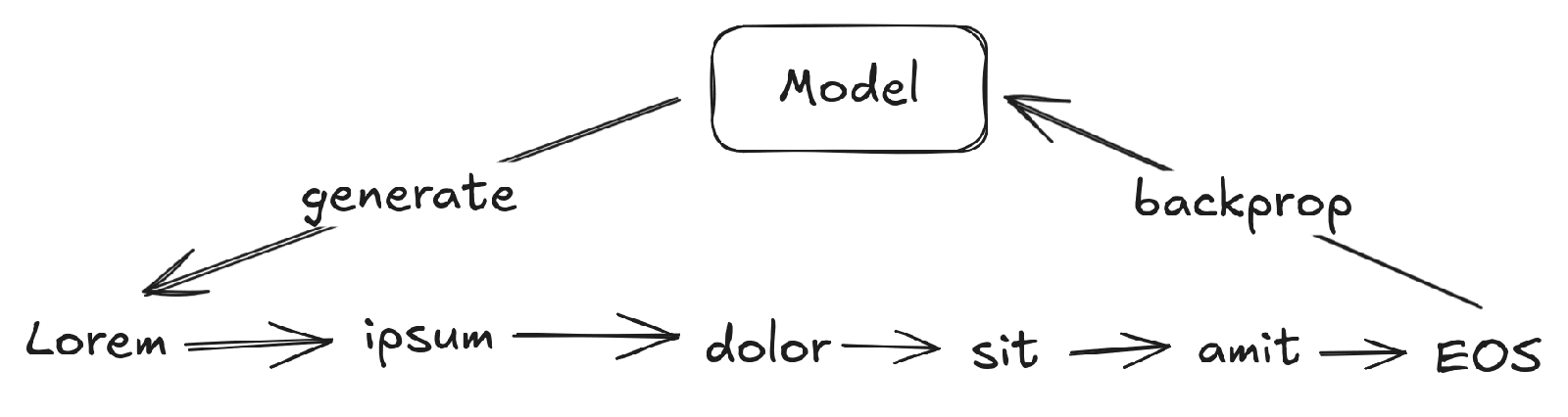
There’s an LLM training optimization which keeps surprising me. It makes loss look unrealistically good during training, especially when training reasoning models with SGD. I’m also starting to think it’s the reason LLMs have trouble fixing their mistakes and take their own outputs too canonically.
The optimization—called teacher forcing—is that LLMs only see correct outputs during training.