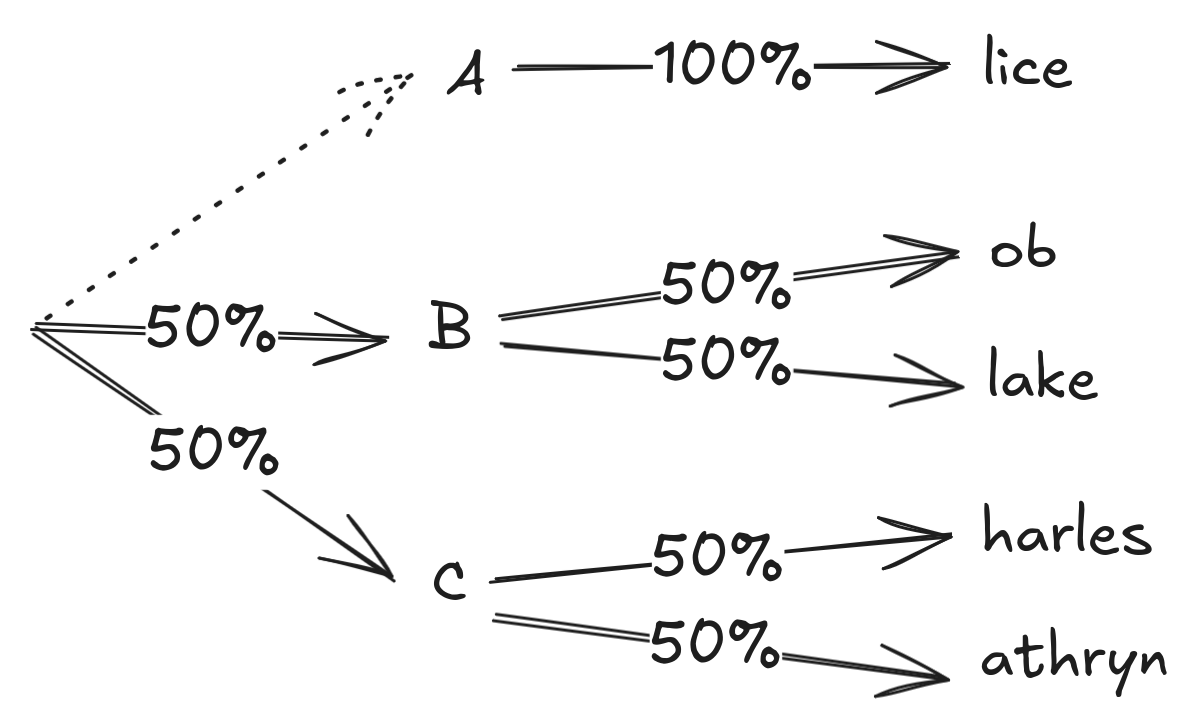
In a recent post, Zvi described what he calls “The Most Forbidden Technique”:
An AI produces a final output [X] via some method [M]. You can analyze [M] using technique [T], to learn what the AI is up to. You could train on that. Never do that.
You train on [X]. Only [X]. Never [M], never [T].
Why? Because [T] is how you figure out when the model is misbehaving.
If you train on [T], you are training the AI to obfuscate its thinking, and defeat [T]. You will rapidly lose your ability to know what is going on, in exactly the ways you most need to know what is going on.
The article specifically discusses this in relation to reasoning models and Chain of Thought (CoT): if we train a model not to admit to lying in its CoT, it might still lie in the CoT and just not tell us.
Read more