It’s that time of year again: Time to make needless improvements to my website. This time, I was annoyed about how my pages were showing up in Google, so I added Microdata1 to my articles. One thing lead to another, and I ended up with Microdata, Open Graph2, a better sitemap, fewer useless pages, and much improved reading mode support.
Microdata
Microdata is a format to mark up HTML with additional semantic data. In the case of this site, I mainly used BlogPosting3. My HTML was already structured properly, so I just needed to add tags to the page templates. Now they generate articles that look like this:
<article itemscope="" itemtype="http://schema.org/BlogPosting">
<header class="post-info">
<h1 class="entry-title" itemprop="headline name">
<a href="./self.html" rel="bookmark" title="Permalink to Article Title" itemprop="url">
Article Title
</a>
</h1>
<p>
<span class="print-only" itemprop="author" itemscope="" itemtype="http://schema.org/Person">
By <span class="author" itemprop="name">Brendan Long</span> on
</span>
<time class="published" itemprop="datePublished" datetime="2015-03-31T00:00:00-06:00">
March 31, 2015
</time>
</p>
</header>
<div class="entry-content" itemprop="articleBody">
<p>Article text</p>
</div>
</article>
The only additions are the itemscope, itemtype, and itemprop properties. I also marked up important images to make it more likely that they would be picked up for thumbnails.
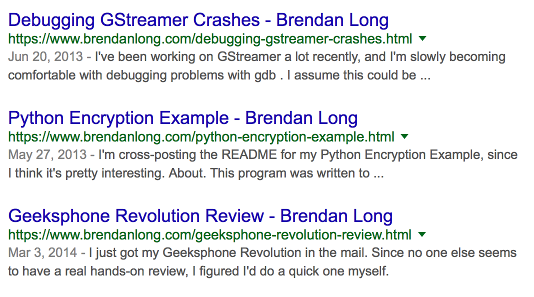
The result is that bots have all of this data4 to look at. On Google5, this ensures that it consistently picks the correct text for the snippet. I was hoping it would also use the article title instead of the page title, but it hasn’t yet.
Note: The crazy print-only stuff is because my site is heavily optimized to print nicely. Since my name is at the top of the site, it’s silly to include it in each article, but I remove the header when printing, so having my name on the article makes sense. Try a Print Preview on this page to see!
Open Graph
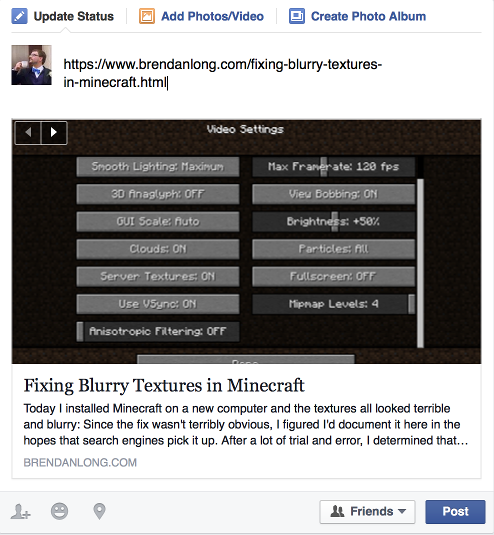
Facebook and Microsoft (and thus Yahoo) use Open Graph to extract information about pages. I figured I might as well add this, since it seems to be more widely supported than Microdata. It was a little harder to work into my templates, since Open Graph data goes in the <head>, but now all of my pages have this information:
<meta property="og:site_name" content="Brendan Long">
<meta property="og:url" content="https://www.brendanlong.com/canonical-path-to-this-page.html">
Anything with a title has og:title:
<meta property="og:title" content="Article or page title">
And blog posts have some extended metadata:
<meta property="og:type" content="article">
<meta property="og:description" content="Same article summary that shows up on index pages ...">
<meta property="article:published_time" content="2015-11-12T00:00:00-07:00">
This is the same info as Microdata, but it gets picked up by Facebook, Firefox, and seemingly Pocket. I didn’t mark up images here because it would be too annoying, and Facebook seems to pick the right images anyway.
Reading mode
Since I was marking things up to make robots parse them better, I figured I should take this opportunity to make my pages look good in reading mode on Firefox, Safari, and Pocket. It turns out that my site already mostly worked, but there were two things that made it work better:
- Put
<article>around articles. Firefox’s reading mode ranks this element higher than<div>when looking for the main content. - Put
class="author"on the<span>with my name. Firefox assumes that this is your name.
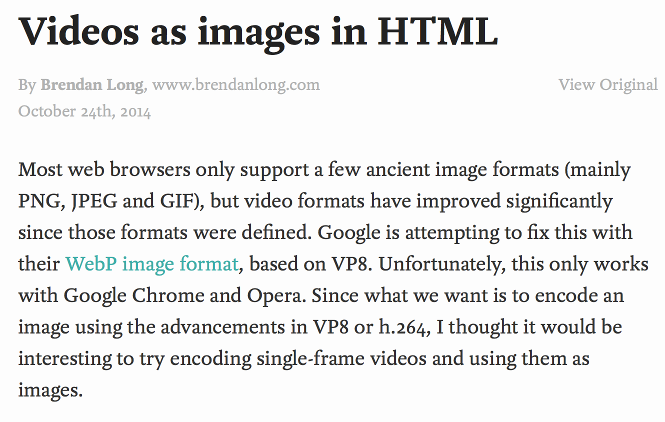
The only problem is that reading mode in Safari and Firefox looks for long pieces of content, so it just won’t work on short posts no matter what. On longer posts it looks great though. Notice in particular how Pocket even picked up the publish date.
De-indexing useless pages
One other thing I noticed while looking at my indexed pages was that there were a lot of weird pages:
- The main blog index pages
- Tag and category indexes
- Per-author (just me!) indexes
- Single page list of all articles (archives)
The only one of these I ever want to show up in search results is the main page. Since I don’t even use them, I just disabled generation of tag, category and author indexes in Pelican:
AUTHOR_SAVE_AS = False
CATEGORY_SAVE_AS = False
TAG_SAVE_AS = False
DIRECT_TEMPLATES = ('index', 'archives')
I decided to keep the archive page around, since if someone really wants to search for “site:brendanlong.com archives,” then more power to them. I might even link to it in the footer one day, since a single page archive is useful for adding posts to Pocket.
With the main indexes, I want them to be crawled but not indexed, so every index except index.html has a new meta tag6:
<meta name="robots" content="noindex">
Due to how this site works, adding the meta tag on specific pages was easier than listing pages in to robots.txt.
I also updated my sitemap7 to indicate that indexes are unimportant (using rank = 0.0):
SITEMAP = {
'format': 'xml',
'priorities': {
'articles': 1.0,
'indexes': 0.0,
'pages': 1.0
},
'changefreqs': {
'articles': 'daily',
'indexes': 'daily',
'pages': 'daily'
}
}
Remaining problems
Of course, readability mode relies heavily on heuristics, so it doesn’t always get everything right. There are two things I’d like to fix, but they’ll probably need changes in Readability.js:
- Detect short articles (possibly using Microdata)
- Consistently remove the date line and footer
https://developers.google.com/structured-data/schema-org - “Intro to How Structured Data Markup Works | Google Search Central | Documentation | Google for Developers”
http://ogp.me/ - “The Open Graph protocol”
https://schema.org/BlogPosting - “BlogPosting - Schema.org Type”
http://linter.structured-data.org/?url=https:%2F%2Fwww.brendanlong.com%2Fbuilding-alljoyn-packages-with-fpm.html
https://www.google.com/search?q=site%3Abrendanlong.com - “Google Search”
https://en.wikipedia.org/wiki/Noindex - “Wikipedia: Noindex”
https://www.brendanlong.com/https://www.brendanlong.com/sitemap.xml